
article
What’s in a name? Exploring demographic bias in data privacy tools like PII masking
Do personally identifiable information (PII) models perform fairly for all individuals?

May 13, 2022 • 10 minutes

May 13, 2022 • 10 minutes

In a time of extensive data collection and distribution, privacy and data security are vitally important to consumers.
However, in 2021, the US-based Identity Theft Resource Center reported a 68% increase in data compromises from the previous year, with 83% involving sensitive data.
The exposure of personally identifiable information (PII), such as names, addresses, or social security numbers, leaves individuals vulnerable to identity theft and fraud. In response, a growing number of companies provide data protection services, such as data masking or PII masking. PII masking is the detection and redaction of sensitive information in data.
At the Second Workshop on Language Technology for Equality, Diversity and Inclusion, we report on how models powering data masking techniques perform across demographic groups such as race, ethnicity, and gender. Historically, the US “Right to Privacy” concept has been centered around Whiteness, initially to protect White women from technology associated with photography (Osucha, 2009). Black individuals have had less access to privacy and face greater risk of harm due to surveillance, including algorithmic surveillance (Browne, 2015; Fagan et al., 2016).
Our research focused on the data masking of names, which are the primary indexer of a person’s identity. To evaluate different PII maskers, we carefully sampled from datasets that included names and demographic information. We found significant disparities in the recognition of names based on demographic characteristics, especially for names associated with Black and Asian/Pacific Islander groups. These disparities are troubling because they put members of these groups at greater risk of exposure and identity theft.
Taking a look at PII masking
In this study, we looked at several PII masking models to see if they perform more or less fairly compared to one another. For example, PII maskers use Named Entity Recognition (NER) models to identify entities for redaction. NER models can locate structured information, such as people’s names, in text. Previous research has shown that these models can have race and gender-based performance differences (Mishra et al. 2020).
Our work focused specifically on PII data masking models which are widely used commercially to protect sensitive data. While previous studies often rely on small samples of names (approximately 100 or less) to investigate demographic bias, we curated one of the largest datasets of its kind with over 4K unique names.
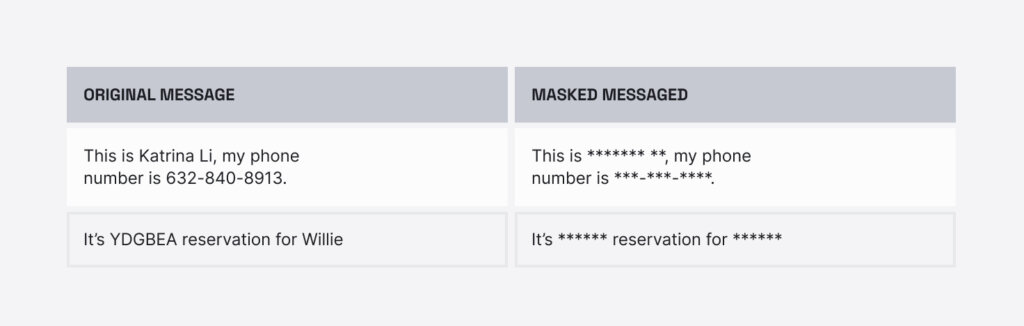
It is important to note that removing names alone is insufficient to fully protect individuals from being identified from sensitive data. Even with names redacted, other information in the data may be used to reveal a person’s identity. However, because names are a primary indexer of a person’s identity and are correlated with various demographic characteristics, this is a useful starting point for auditing PII masking models for bias.
In some contexts, recent PII masking models have performed very well. The deep learning model developed by Dernoncourt et al. (2017) was able to redact 99% of names in patient discharge summaries. However, the commercial models we analyzed did not achieve such high performance on our dataset.
So, what’s in a name (besides sensitive data)?
Naming conventions vary due to cultural and linguistic contexts. In many cultures, names are gendered, and names may be associated with a particular religious or ethnic group. Previous research has uncovered racial and gender bias from studying names. Bertrand and Mullainathan (2004) found that, given identical résumés with only a change in name, résumés with Black-associated names received fewer callbacks than White-associated names. Sweeney (2013) found that internet searches for Black (in contrast to White) names were more likely to trigger advertisements that suggested the existence of arrest records for people with those names.
In this study, we manipulated names to understand whether the performance of PII masking models correlates with the race, ethnicity, or gender associated with particular names. We looked at discrepancies in model performance where sensitive data (i.e. names) was not appropriately masked. Then we defined model bias in terms of significant performance differences between demographic groups.
One important point is that it’s not possible to identify someone’s gender, race, or ethnicity by looking at their name.
Instead, we categorized which names were associated with a particular gender, race, or ethnicity in the data. First, we gathered large datasets of names with self-reported demographic information. If most people with a certain name self-identified within the same group (more than 75% for a certain race/ethnicity and 90% for a certain gender), then we said that name is “associated” with that group. If names within a group were misclassified at a higher rate than other groups, we argued that members of those groups carry a higher privacy risk.
First, consider what the templates tell us
We collected a set of 32 templates from real-world customer service messaging conversations, including dialog between customers and Conversational AI or human agents. The topics of discussion included scenarios like tracking a purchase or paying a bill. This data is especially vulnerable to security threats, carrying potentially sensitive personal information such as credit card or social security numbers. We replaced each name in the dataset with a generic NAME slot.
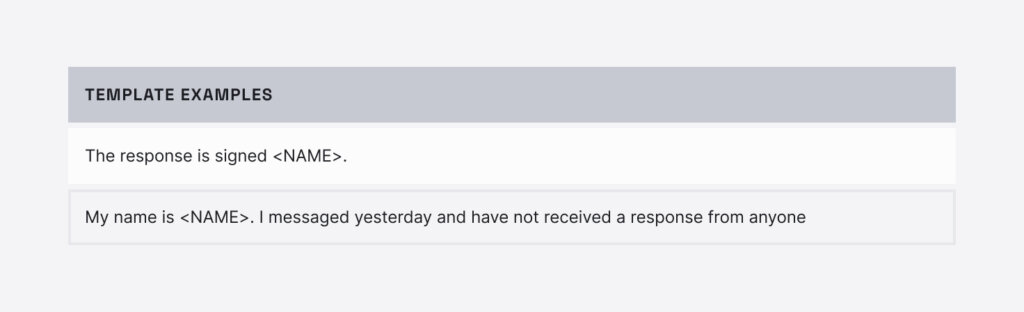
What the overall data tells us
Next, we filled in the slots with names from the data records we collected which included associated demographic information. This allowed us to measure performance across race, ethnicity, and gender. This technique has been used in previous studies to test the performance of models across sensitive groups (Garg et al., 2019; Hutchinson et al., (2020).
We did not use full names of real people in our investigation for privacy concerns. Instead we looked at given (or first) names in datasets, which included aggregate demographic information. We also used the full (first and last) names of US Congress members, whose identity and self-reported demographic information is publicly available.
NOTE: In some cases, we didn’t evaluate all of the race and ethnic categories reported in each dataset because there weren’t enough samples to generate reliable statistics. Similarly, we only reported on binary gender categories. However, additional groups are reported in our paper.
- The Congress dataset includes the full names of the 540 current members of US Congress. This includes 27% women and 73% men from 5 different race and ethnicity categories.
- The LAR dataset from Tzioumis (2018) contains given names with self-reported race/ethnicity from US Loan Application Registrars (LARs). It includes 4.2K names from 2.6M people across the US. There are some limitations to this dataset, though. Because it’s taken from mortgage applications, and there are known racial and socioeconomic differences in who submits mortgage applications (Charles and Hurst, 2002), the data may contain representation bias. However, it’s the largest dataset of names and reflects nearly 86% of the US population (Tzioumis, 2018). Since the dataset is so large, we were able to control for how popular names were across race and ethnicity groups. In this way, we know that differences weren’t simply due to the popularity of names associated with a particular group.
- The NYC dataset was created using the New York City (NYC) Department of Health and Mental Hygiene’s civil birth registration data (NYC Open Data, 2013). It contains 1.8K given names from 1.2M children. Data includes the sex of the baby and the race/ethnicity of the birth mother. We did an intersectional analysis on this dataset to examine how gender and race/ethnicity together correlate with model performance.
While the other datasets report on adult names, the NYC data includes the names of children who are currently between 4-11 years old. This adds diversity in terms of age, as data privacy is an important issue for both children and adults.
Our overall data masking evaluation
We selected two commercial and one open-source data privacy systems for evaluation of their data masking techniques. The commercial systems come from two leading cloud service providers. We chose these systems for their potentially large reach, holding a combined 43% market share of cloud services. We also evaluated an open-source model for data protection. The open-source system uses a spaCy transformers model for NER, which utilizes the RoBERTa-base Transformer model. (The commercial models do not offer implementation details.)
For metrics, we measured false negative rates (FNRs). This is the rate at which a PII masking service is unable to mask a name in the dataset. We also measured the statistical significance of performance differences across subgroups.
What we found: The overall PII masking results
Looking at the results of the PII masking services across all datasets, we found significant differences in performance based on race/ethnicity and gender. The open-source model performed more equitably than the commercial systems. However, all systems had performance differences according to race and ethnicity.
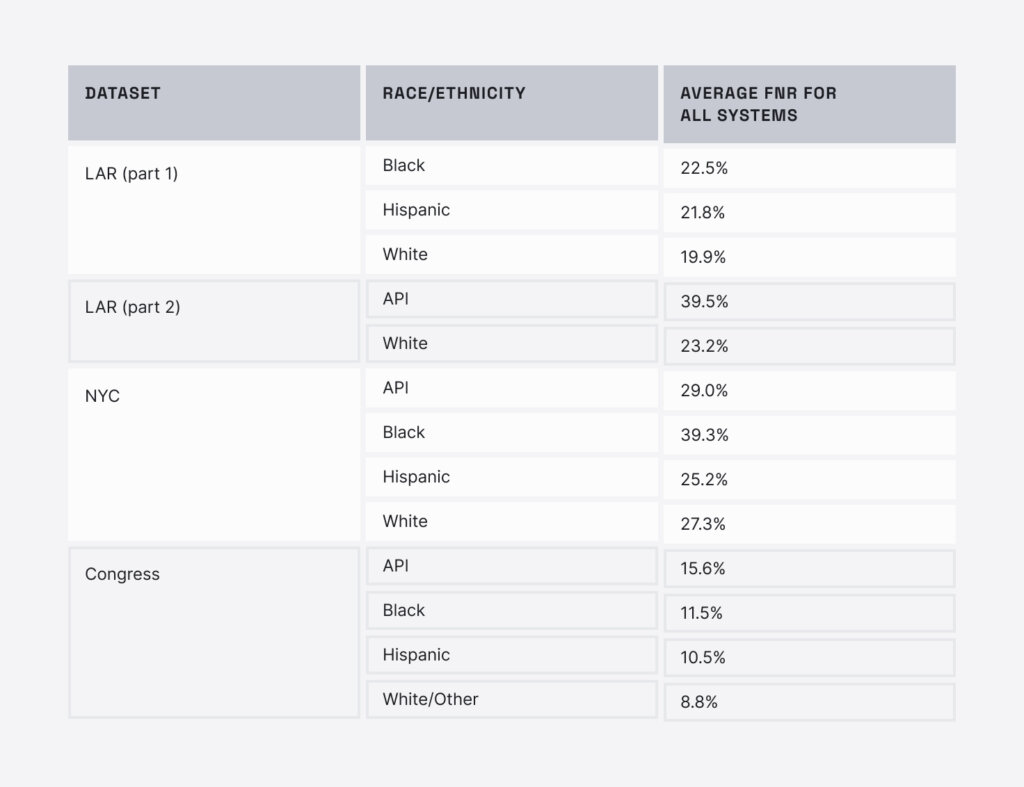
For every dataset, Asian and Pacific Islander (API) and Black-associated names had higher error rates than Hispanic and White-associated names. Some of the PII maskers failed more than ⅓ of the time for these groups.
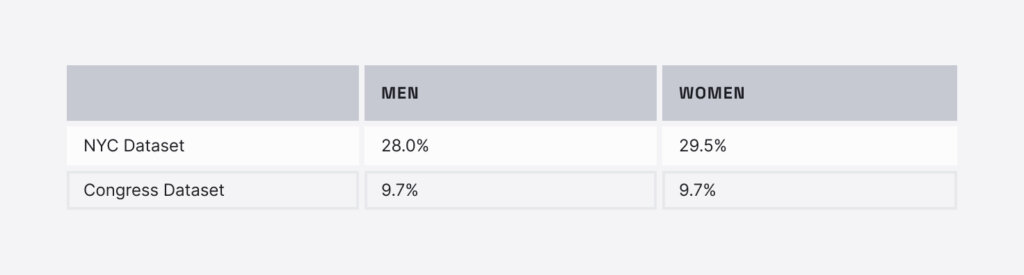
The error rates for names associated with men vs. names associated with women were similar. However, individual PII masking systems showed different patterns. For instance, one commercial system had better performance on names associated with women, while another had better performance on names associated with men.
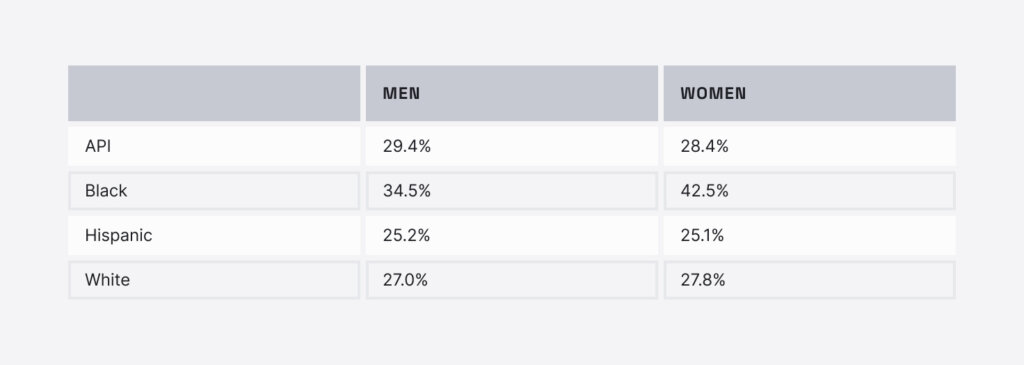
In this last table, we show intersectional results over the NYC dataset. For most race and ethnic groups, the performance of the models for names associated with men and women were similar. However, we saw much higher error rates for names associated with Black women (42.5%) than Black men (34.5%). In fact, Black women had the highest error rate across all intersectional groups.
Further analysis of names showed that some characteristics are related to poor performance by PII masking systems. For instance, shorter names often were not masked correctly. However, shorter White-associated names had lower error rates than API or Black-associated names of the same length. Some names are ambiguous with other words in English (for instance, ‘Georgia’ can refer to a person’s name or a U.S. state). We found that these kinds of ambiguous names were more difficult for the PII masker, but racial and ethnic differences still remained. As an example, Black-associated names of this type are more error-prone than others. The API-associated “Joy” has a 60% lower error rate than the Black-associated name “Blessing.”
Conclusion: Data masking techniques have room to grow in gender and ethnic inclusion
We analyzed three PII masking services on names that are associated with different demographic groups. In doing so, we found that there were disparities in fairness based on the degraded performance of the model for names associated with certain groups of people. Generally, names associated with Asian and Pacific Islander and Black people, especially Black women, were not masked as well as others. Our research shows that these groups may be at greater risk of data privacy issues.
Identifying this type of algorithmic unfairness is the first step toward bias mitigation. Our mission is to build more inclusive models that work for all people.
This blog post is summarized from the full report, “Behind the Mask: Demographic bias in name detection for PII masking,” researched and written by Courtney Mansfield, Kristen Howell, and assisted by Amandalynne Paullada.